
人们把词语组合成句子来表达意义,对于一句中文,人可以借助知识明白哪些是词,进而理解语句的含义,而计算机很难做到。确定句子中的词,是计算机理解中文的基础。jieba库是一款优秀的Python第三方中文分词库。
jieba库的安装
因为 jieba 是一个第三方库,所以使用前需要进行安装。
Windows
pip install jieba
pyCharm
打开 settings,搜索Project Interpreter,在右边的窗口选择 + 号,点击后在搜索框搜索 jieba ,点击安装即可。
中文分词
把一段中文拆分成词的过程,叫做中文分词。 它是解决中文语义分析,信息检索等问题的基础。
一段/惊心动魄/的/旅程/开始/了
研究/生命/的/起源
在python中进行中文分词,可以借助jieba库。
三种模式
jieba是中文分词库,库中包含一个中文词典,根据这个词典,它可以找到句子中所有可能的词语组合,并分析出一个可能性最大的拆分结果。
jieba库支持三种分词模式:
精确模式:lcut(str)
把文本精确地切分开,不存在冗余单词。
适用于文本分析。
例: [‘一切’, ‘戛然而止’] 一切戛然而止
全模式:lcut(str, cut_all=True)
把文本中所有可能的词语都扫描出来。
速度快,存在歧义和冗余。
例:一切戛然而止 [‘一切’, ‘戛然’, ‘戛然而止’, ‘然而’, ‘止’]
搜索引擎模式:lcut_for_search(str)
在精确模式的基础上,对长词再次进行切分。
适用于搜索引擎分词。
例: [‘一切’, ‘戛然’, ‘然而’, ‘戛然而止’] 一切戛然而止
进行文本分析要采用精确分词模式,可以借助lcut()命令。

lcut()命令会返回存储分词结果的列表。
lcut()使用格式
先导入jieba库,才能使用库中的lcut()命令。
import jieba //导入jieba库
jieba.lcut(str) //使用库中的命令分词
例如:
import jieba
words = jieba.lcut('我喜欢编程')
print(words)
输出
[‘我’,’喜欢’,’编程’]
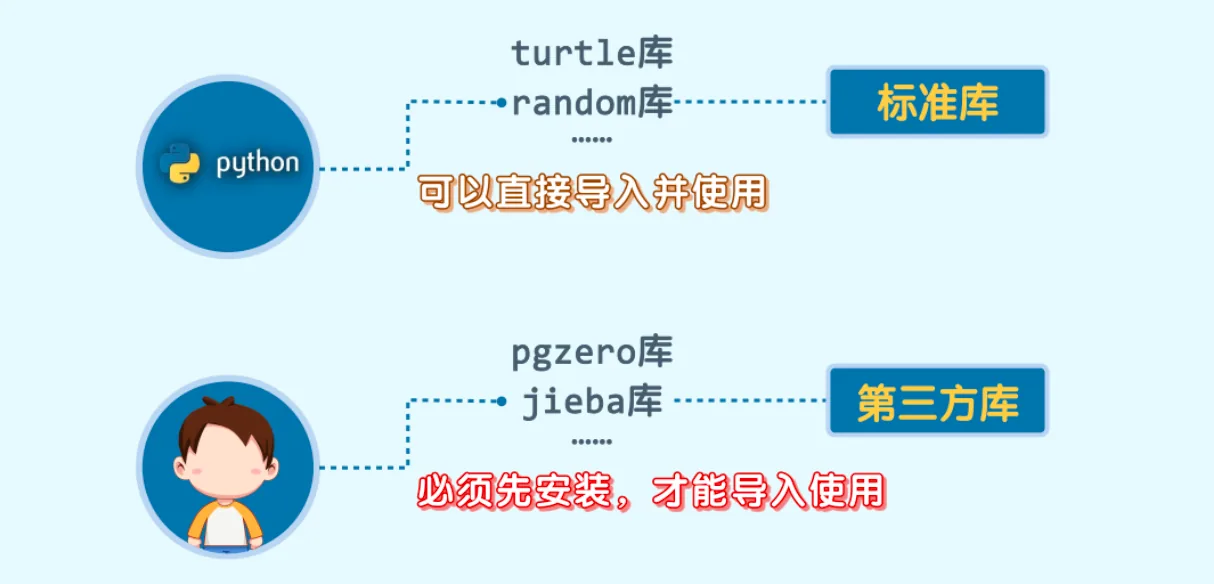
第三方库
jieba库是一个第三方库,因为它既不是python自带的,也不是我们自己在程序中编写的,而是由其他人提供的。
python自带的库,也叫做标准库,可以直接导入并使用; 而第三方库,必须先安装,才能成功导入和使用。

多参数函数
在定义函数时,可以设置多个参数。
def 函数名(参数1, 参数2, 参数3, ...... ):
语句1
语句2
......
return 结果
在调用函数时,需要传入对应的参数。
函数名(参数1, 参数2, 参数3, ...... )
定义时
def search(text, world):
res = []
for i in range(len(text)):
if word in text[i]:
res.append(i + 1)
return res
text用来接收存储文章 每一行内容的列表
word用来接收要 查找的词语
调用时
rows = search(lines,x)
lines传入存储文章 每一行内容的列表
x传入要查找的词语
return语句
在定义函数时,使用return语句返回函数的运行结果。
def 函数名(参数1, 参数2, 参数3, ...... ):
语句1
语句2
......
return 结果
执行return语句后,函数运行结束。
def 函数名(参数1, 参数2, 参数3, ...... ):
语句1
语句2
......
return 结果1 //执行这条return语句后, 函数运行结束。
return 结果2 //不会执行这条return语句
执行return语句,函数结束执行,函数只能返回词语第一次出现的行号。




暂无评论