
制作词云图
任务目标
使用python完成一个小程序,分析鲁迅先生文章中 最常用的词语,并使用词云图展示出来。
按照功能将程序分为3个模块: 读取数据、分词处理、制作词云图
读取数据—文件操作
文件操作有3个步骤:打开文件、读取文件、关闭文件。
• 打开文件:
f = open('文件名', '打开模式', encoding='utf-8')
• 读取文件:
text = f.read()
• 关闭文件:
f.close()
分词处理
读取到文章后,使用jieba库对文章进行分词处理。
• 导入jieba库
import jieba
• 分词处理
分词结果 = jieba.lcut(字符串)
制作词云图
词云图可以展示文章中的高频词。词语在文章中出现的次数越多,在图中就会显示得越大、越醒目。
制作词云图的3个步骤
创建词云对象、加载词云文本、保存词云图片
• 创建词云对象:
w = wordcloud.WordCloud()
• 加载词云文本:
w.generate(s)
• 保存词云图片:
w.to_file('词云.png')
制作词云图需要加载的文本应该是字符串类型的,并且词语之间需要由空格或标点符号隔开。
使用join()函数,来生成制作词云图用的文本。
s = ' '.join(列表)
散文.txt ==> 鲁迅先生《朝花夕拾》
import wordcloud
import jieba
//读取文件,得到文章内容
f = open('散文.txt','r', encoding='utf-8')
text = f.read
f.close
words = jieba.lcut(text) //对文章进行分词
s = ' '.join(words) //将得到的词语用空格连接得到词云文本
mac = 'PingFang.ttc'
win = 'simhei.ttf'
sw = {'我们', '他们', '没有', '一个', '就是', '因为', '所以', '然而'}
//创建词云对象
w = wordcloud.WordCloud(
width=300,
height=300,
background_color='white',
collocations=False,
stopwords=sw,
font_path=win
)
w.generate(s) //加载词云文本
w.to_file('词云.png') //保存词云图片

绘制柱状图
任务目标
分析鲁迅先生的文章中出现了哪些城市,并将它们的出现次数绘制成柱状图展示出来。
从分词结果中,将城市名称筛选出来,再统计出现次数,最后绘制成柱状图。
筛选数据
想要从大量词语中,将城市名称筛选出来。
可以先创建一个城市名称列表,判断词语是否在列表中。如果在列表中,就说明该词语是个城市名称,就将它筛选出来,添加到新列表中。
城市名称存储在文件 城市.txt 中,每个城市名称由空格隔开。
import jieba
//读取文件,得到文章,并进行分词
f1 = open('散文.txt','r', encoding='utf-8')
text1 = f1.read()
f1.close()
words = jieba.lcut(text1)
//读取文件,得到城市名称列表
f2 = open('城市.txt','r', encoding='utf-8')
text2 = f2.read()
f2.close()
names = text2.split()
cities = []
//从分词结果中筛选城市名称
for w in words:
if w in names: //判断词语是否在城市名称列表中
cities.append(w) //如果是城市名称就添加到新列表中
列表cities中存储了分词结果中所有的城市名称。创建一个空字典,用来存储统计结果。
counts = {}
for w in cities:
if w in counts:
counts[w] += 1 //如果词语在字典中,就将对应的出现次数增加1
else:
counts[w] = 1 //如果词语不在字典中,将它添 加到字典中,并将对应的出现 次数设置为1
字典counts中存储着统计结果,其中字典的key是城市名 称,value是对应的出现次数。
柱状图
pyplot.bar(x轴数据, y轴数据)
绘制图表有3个步骤:
准备数据、画图、展示图表 x、y轴数据为列表类型的。
x轴数据为字典 counts 的 key;
y轴数据为字典 counts 的 value。
准备数据
字典名.keys() 得到字典的所有key
字典名.values() 得到字典的所有value
得到的并不是列表类型的数据
使用list()函数将数据转换为列表类型。
from matplotlib import pyplot
pyplot.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'simhei']
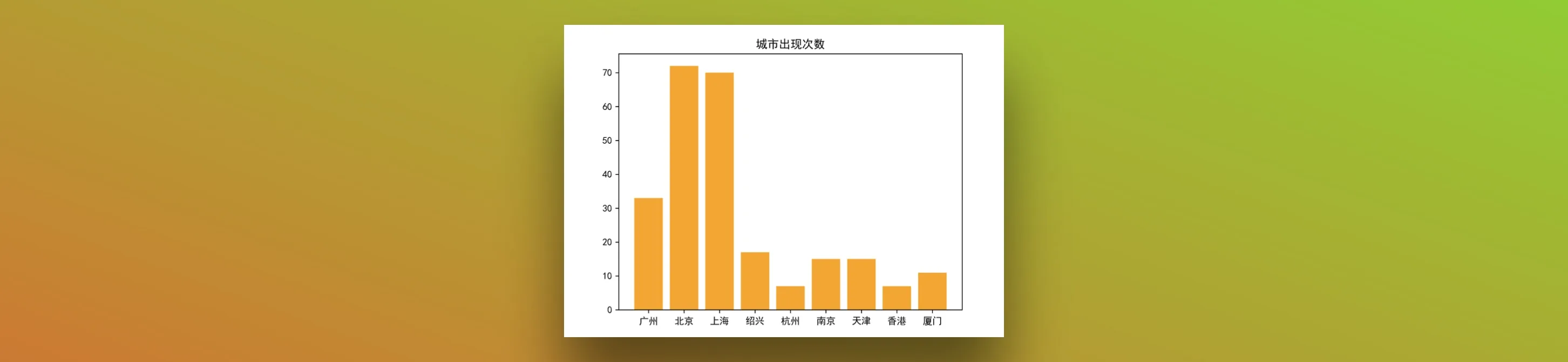
counts = {'广州':33, '北京':72, '上海':70, '绍兴':17, '杭州':7, '南京':15, '天津':15, '香港':7, '厦门':11}
c = list(counts.keys())
n = list(counts.values())
pyplot.bar(c, n, color='orange')
pyplot.title('城市出现次数')
pyplot.show()





你在往Python大佬发展呀😳
大佬,这连入门都还没到?
人生苦短,我用Python
人生苦短,我们要学Python 😂